Reinforcement Learning. What and Why?
Back in 2015, AlphaGo, an AI-powered system played the Game of Go against Mr.Fan Hui and Mr.Lee Sedol, the best players of the game, beating them both. This marked a historical accomplishment in the AI-world as it was the first time a machine was able to beat the best of humans in their own game.
Even in Chess, AI-powered systems have been able to gain wins over human players. This is all part of Reinforcement learning. These results are nothing short of amazing. RL is not only used to beat humans at games, it is used in different areas of Computer Science and Technology. Eg:-
- Power systems – to predict and minimize transmission losses and enhance Microgrid performance..
- Medical image segmentation - optimally finding the appropriate local thresholding and structuring element values and segment the prostate in ultrasound images.
- Robotics - navigation in indoor environments.
What is Reinforcement Learning?

© facebook.com/brevitycomic
Before we jump onto the definition, let’s go through an analogy that’ll help us build an intuition.
Suppose that you own a dog, how would you train your good boy? Most likely by telling him what to do and if he does it you’ll reward him by giving a cookie. Otherwise wait until he performs the action. If you tell him to roll and he does it, then a cookie. But for some action like tearing up the newspaper, you might give him a time out. So basically, reward for correct action and punishment for wrong ones.
We follow same strategy in RL. In RL, our software agent is concerned with it’s actions in order to maximize the reward. In much simpler terms, RL is learning what we do and how to map situations to actions in order to maximize a numerical reward. The catch here is that the model is never told what to do but left to discover itself by trying out different options and figure out which action yield better reward. This follows nearly the mechanism of a biological Neural network. Why do I say so? Because we tend to learn and perform better when given reward for our actions.
There are some terms that we need to know before actually diving deeper. That’ll give us a complete overview of how things are in RL.
- Agent: A system that takes actions to change the state of the environment and gain rewards.
- Environment: The external system that an agent is embedded in, and can perceive and act on.
- Reward: A scalar value which represents the degree to which a state or action is desirable.
- State: This can be viewed as a summary of the past history of the system, that determines its future.
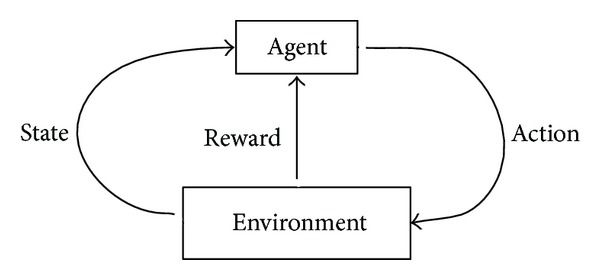
There are other subelements like policy, model and reward signal but we’ll take those into account later.
How is it any different from Supervised and unsupervised learning?
Supervised learning is the area of machine learning where learning is done from a training set of labeled examples provided by a knowledgeble external supervisor. Each label is described as a situation with a specification of the correct action the system should take. The sole objective of this is that the system should generalize the responses to certain situations that are not present in the training set. In interactive problems, this approach is not desirable where examples are both correct and represents all the situations an agent has to act upon.

© xkcd.com
It might be possible to mistake RL as a kind of unsupervised learning. Unsupervised learning is the mechanism of inferring a function that describes the structure of unlabeled(neither classified nor categorized) data. So bascially, we try to find some kind of structure and pattern hidden in our data. What makes Reinforcement learning different is it’s focus on trying to maximize a reward signal instead of trying to find hidden structure. Yes, finding the structure for an agent can be useful but it will not address the problem of maximizing the numerical reward.
Why Reinforcement Learning?
At the very beginning, I pointed out the power of RL based models and some use cases. But are these all that we can do? NO. There’s a lot more to it.
Being influenced by deep learning techniques, it has it’s way to optimize results in supervised problems. It has also been used to implement attention techniques in Image processing. Incorporating deep learning techniques and Reinforcement leraning methods work really well and has proved to be efficient in a lot of different problems. One cannot deny the power of Reinforcement Learning.

© xkcd.com
This blog is a very basic overview of what is RL and why is it important. I’ve been following Richard Sutton’s and Andrew Barto’s Reinforcement Learning: An Introduction and as I proceed, I’ll write the gist of every topic explaining the concepts. Perhaps try to solve the exercises and write codes for the algorithms described in the book.